Normalisation
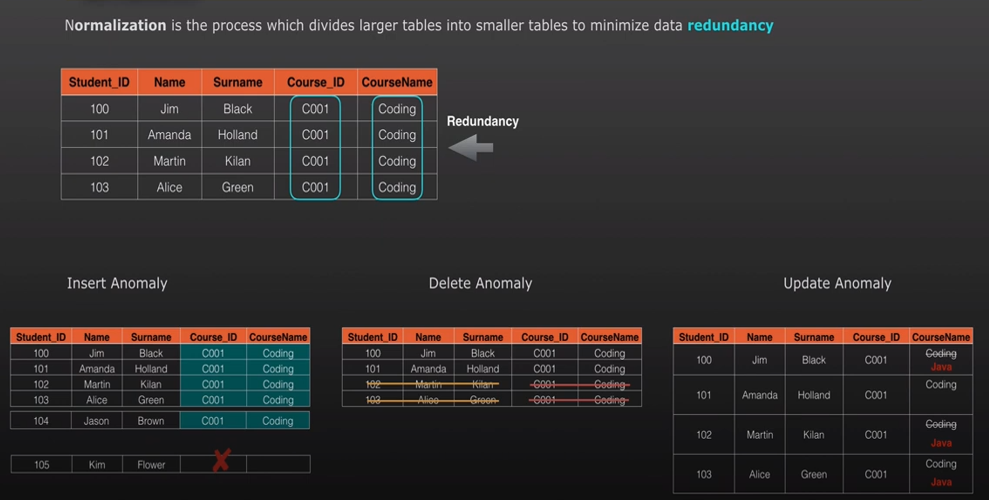
- Normalisation is a process which divides larger datasets into smaller to minimise data redundancy
- Eliminate insert / update / delete anomalies
Insert anomaly example: If a student record and Course details stored together and when we just want to add only new student without a course or add a course details without a student, both cases causes trouble.
Update anomaly example: If a table contain 1000’s of students and if there is a change to the course name instead of updating one record, we have to update several student records i.e. when the course details are already embeded with student details. Also there is a chances of missing updates to some of the rows if the task fail in the middle and no rollback occurred.
Delete anomaly example: If we delete a course details there is a risk of loosing the student records and vice versa.
Normal Forms
1NF – First Normal Form – All columns must be atomic, but when solving this issue we introduce redundancy.
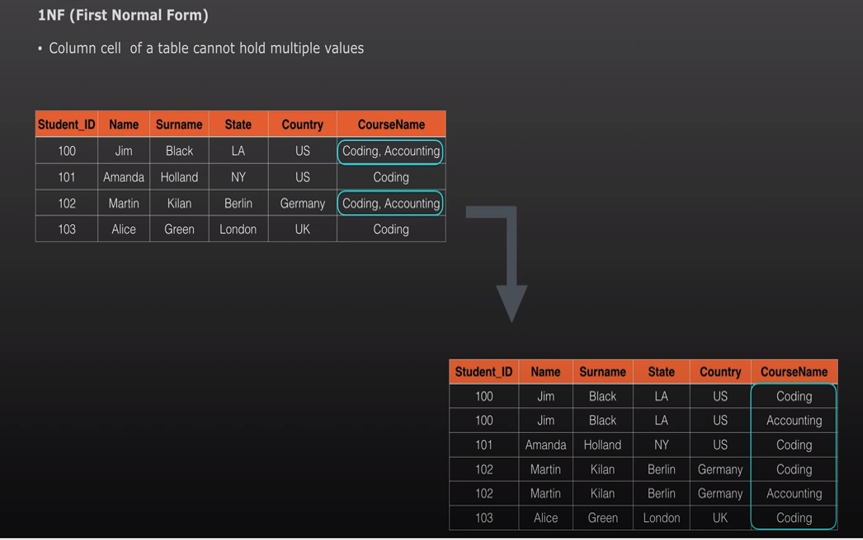
Example: Course Name column values: Coding, Testing, Design. If a student enrolled in all of these then the course name contain all of the above values with comma separator. This violates the 1st normal form.
To resolve we store the same student single record into three records i.e. one row per course name.
Now the student record is getting repeated and introduced redundancy.
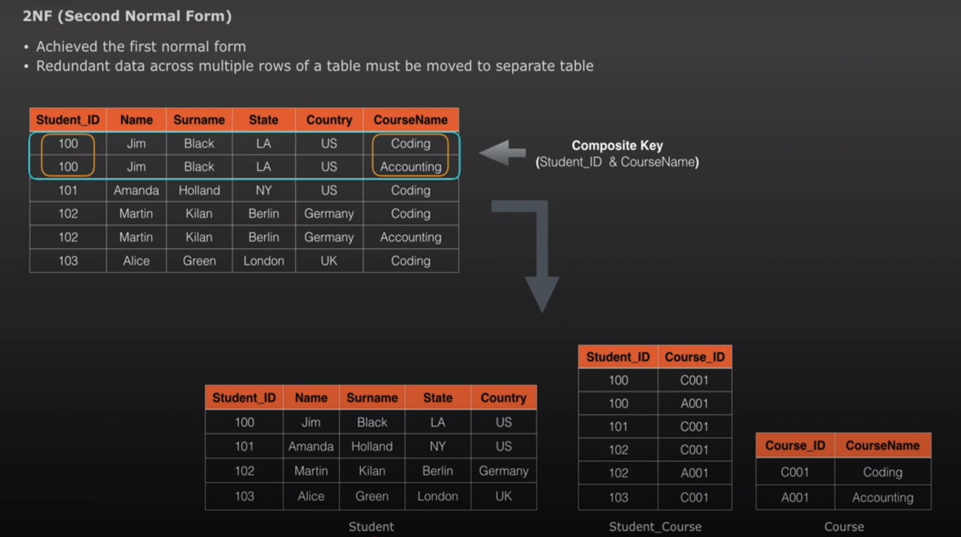
2NF – Second Normal Form – 1NF + Composite key shouldn’t be the reason for duplicates. So break it and also create a bridge table to handle many to many relationship between student details and course details. i.e. redundant data across multiple rows must be moved to a separate dataset.
example – If the Student_ID and Course_ID forms the uniqueness then split them into separate table and create a bridge table to display the relationship.
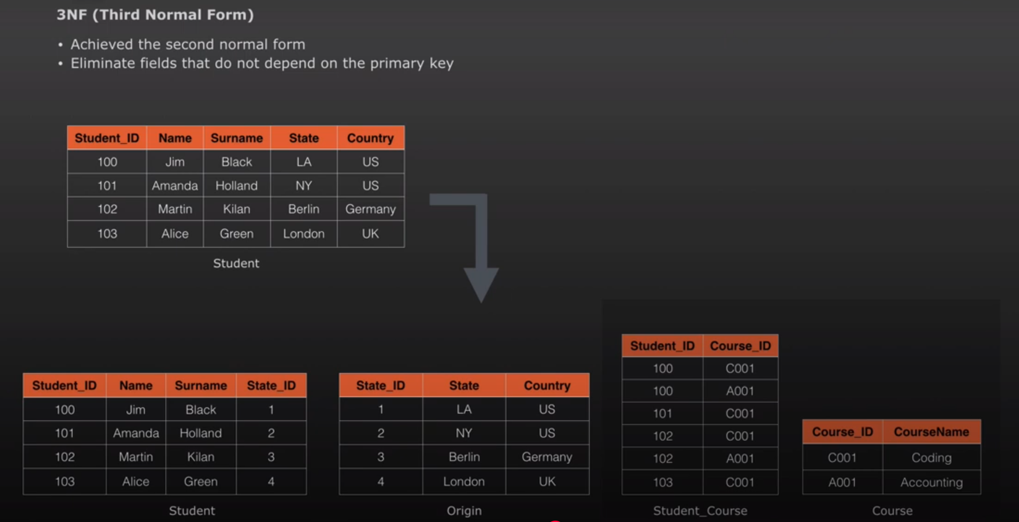
3NF – Third Normal Form – 2NF + Columns that are not directly dependant on primary key or Non key attributes dependant on another non key attribute then they are stored in a separate dataset.
DeNormalisation
Optimisation technique applied after normalisation for faster reads. Denormalisation is a process where data from multiple tables are combined into one table, so that data retrieval will be faster.
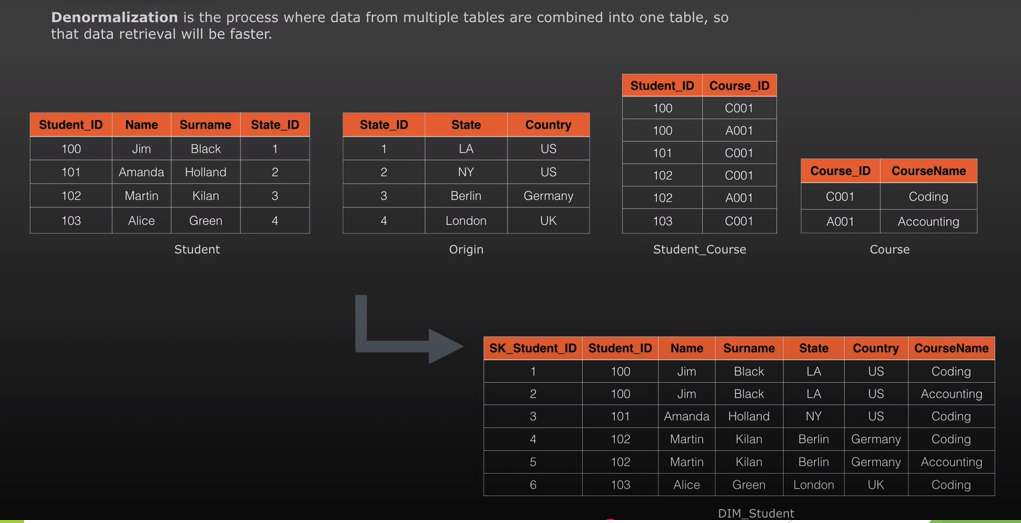
Normalisation vs DeNormalisation
Normalisation
- Normalisation divides larger datasets into smaller and reduces redundancy
- Increased number of tables and hence increased the number of joins needs for data reterival
- Faster writes and updates
- Used in OLTP system
DeNormalisation
- Denormalisation combine smaller datasets into larger one
- Less Joins
- Faster reads, because combining smaller datasets into larger one through the ETL process helps the users to read and analyse the data faster
- Used in OLAP system

Other Topics to be added
Bigdata
3 Vs
Volume (Larger Volume of data)
Variety (Structured, Semi Structured and UnStructured)
Velocity (Batch, Near Real Time, RealTime – different frequency of data arrival and updates)
Full Load vs Change data capture (CDC)
End of Day snapshot vs Intraday state changes to support analytical needed
Why no separate documentation is needed when working in dbt Cloud: When working with dbt Cloud, you typically do not need a separate data dictionary because dbt itself generates comprehensive documentation about your data models, including details about columns, data types, and descriptions, effectively acting as a built-in data dictionary that updates automatically with each run; therefore, you can leverage dbt’s documentation features instead of maintaining a separate data dictionary.
But is is up-to the project team who maintain the relevant details in the form of .md and .yaml files.
dbt helps
- develop
- test
- document
- deploy
Advantages of dbt
- Orchestration
- lineage graph
- git integration
- user authentication / SSO